
设计软件是一个不断产生疑问、解决疑问的过程。设计者们面对一个需求,会产生许许多多的疑问,在这些疑问中,有一个看似幼稚,却直击灵魂的小问题:“业务逻辑(复杂度)放在哪?” 项目每引入一个新功能,所增加的总复杂度几乎是确定的,但如何把这些复杂度分配到各模块中,其中的方式方法却变化无穷。
比如,一个采用“客户端/服务端”架构的软件,在增加某项业务功能时,工程师们可能会发现:它既可以(主要)放在服务端实现,也可以放在客户端实现。不同决策直接影响后续的分工模式、开发效率以及功能扩展性等方方面面。
此类场景中,一种常见的设计策略是 “瘦客户端,胖服务端” ,“胖/瘦”指的并非身材,而是组件所承担的职责多寡。采用“瘦客户端”设计,代表主要的业务逻辑均由服务端承担,客户端尽量简单。
让我们通过 kubectl apply 命令的故事,看看如何把“瘦客户端”理念应用在现实世界的软件中。
kubectl apply 的故事
作为当下最流行的容器编排系统,Kubernetes 最为人所熟知的设计之一,是它的声明式资源配置功能。简单来说,人们将应用的“目标运行状态”写进一份 YAML 文件,然后执行 kubectl apply,Kubernetes 便会遵循描述,将应用运行起来。
举个例子,以下是一个简单的 Nginx 应用的 Deployment 资源描述:
# test_nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
annotations:
the_app_name: nginx # *一个小小的注解,“后面会考”*
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
对该文件执行 kubectl apply,之后稍等片刻,便可以看到 nginx-deployment 正常运行在了集群中。之后,如果想要对该资源进行任何调整,只需修改 test_nginx.yaml 文件,重新执行 apply 命令即可。
下面做一个小小的实验,来深入理解 kubectl apply 命令的能力。
首先,执行 kubectl get 来查看集群中的资源定义:
❯ kubectl get deploy -o yaml
apiVersion: v1
items:
- apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
kubectl.kubernetes.io/last-applied-configuration: ...
the_app_name: nginx # YAML 文件中定义的注解
# ... 已省略 ...
主要观察该资源的注解(annotations)部分。
Tip:注解(
annotations)是 Kubernetes 中的一个通用资源字段,保存了一些对系统运行有用的信息,它采用键值对结构,可以简单当成一个 Python 里的字典或 Go 中的map[string]string。
可以看到,之前定义在 test_nginx.yaml 文件中的注解项 the_app_name: nginx 正常出现在了资源中。除此之外,注解字段中还有几个新面孔,比如 deployment.kubernetes.io/revision 等。它们并未定义在 YAML 文件里,而是在资源被提交后,由 Kubernetes 的系统组件(比如 Deployment Controller)写入,可以被统一归为“系统注解”。
然后,我们修改 test_nginx.yaml 文件,将其中的注解 the_app_name 改个名,改成 the_name_of_app:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
annotations:
# 已删除:the_app_name: nginx
the_name_of_app: nginx
# ...
之后重新执行 kubectl apply 命令,然后查看集群中的资源定义:
❯ kubectl get deploy -o yaml
apiVersion: v1
items:
- apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
kubectl.kubernetes.io/last-applied-configuration: ...
the_name_of_app: nginx
# ...
可以发现,改动已经生效,注解字段中的 the_app_name 成功被替换为了 the_name_of_app。
回顾前面的整个 “apply -> 修改 -> 重新 apply” 的过程,会发现它非常符合直觉。如果再仔细思考,你会发现里面暗藏玄机。
比如,在最后一次执行 apply 命令时,Kubernetes 服务端接收到的 YAML 实际只有一个注解键:the_name_of_app,没有其他信息,但最终服务端决定用它来替换 the_app_name,而不是增加一个新的注解键,为什么?此外,服务端又是如何在更新注解(annotations)字段时,避开那些“系统注解”的呢?
以上这些,全都要归功于 kubectl apply 的实现。
客户端侧 apply
如前所述,kubectl apply 的职责是将一份资源定义“应用”到集群中,但它并非用本地定义完整替换服务端的资源(这样会影响到那些“系统注解”),也不是简单地打一个没头没脑的补丁(这样就无法感知到“旧注解” the_app_name 应被删除)。
为了让结果符合用户预期,kubectl apply 采用了一种类似于“智能打补丁”的方式。具体来说,在每次执行 apply 命令时,kubectl 客户端会先读取以下 3 份数据:
- 本地文件中的资源定义(
test_nginx.yaml) - 服务端上次被 apply 的完整资源定义(从系统注解
kubectl.kubernetes.io/last-applied-configuration中获取) - 服务端目前活跃的资源定义(
kubectl get ...看到的内容)
基于这些数据,客户端使用一种名为“三路合并(3-way merge)”的算法生成一份最符合逻辑的资源补丁对象(patch)。以前面的小实验举例,步骤如下:
- 客户端读取服务端的资源定义
- 客户端读取本地文件中的资源定义,发现注解
the_name_of_app: nginx - 客户端获取服务端上一次
apply的资源定义,发现注解the_app_name: nginx - 基于以上 3 份数据,
kubectl产生最符合逻辑的 PATCH 对象:{"the_app_name":null,"the_name_of_app":"nginx"}——删旧添新
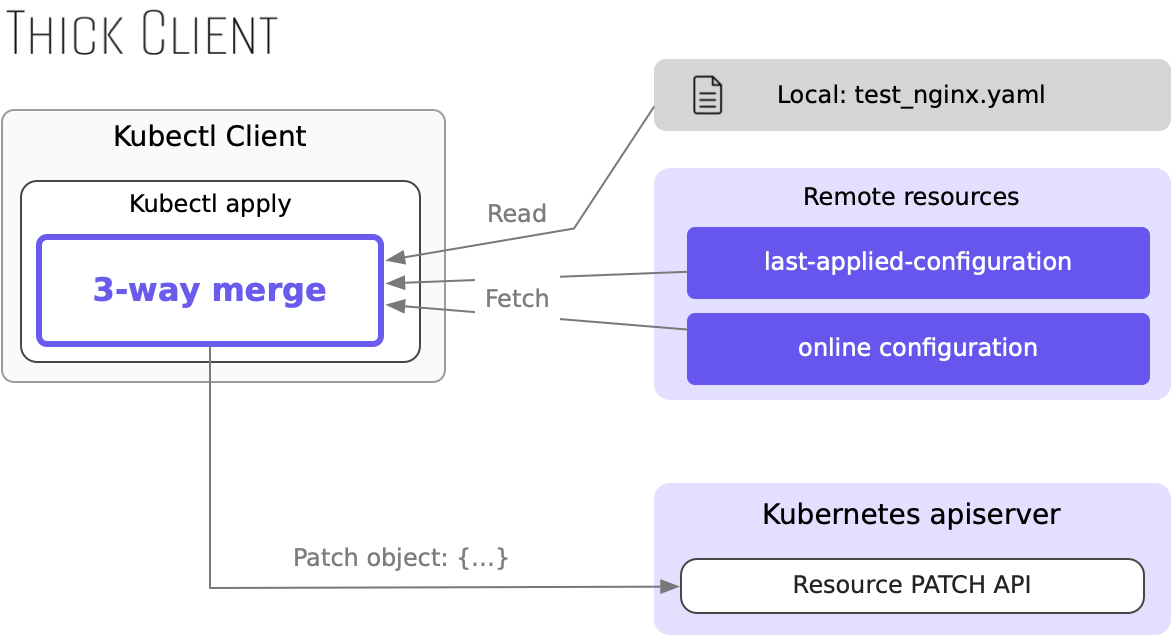
因为以上整个过程主要在客户端完成,服务端仅提供基础的读写 API 支持,采用这种工作模式的 kubectl apply 也被称为“客户端侧 apply(client-side apply)”。
客户端侧 apply 的局限性
就像前面所演示的,客户端 apply 很好地满足了用户需求。但是,随着时间的推移,越来越多的人发现这种模式存在许多局限性。最显著的,当时其羸弱的冲突处理能力。
一份资源定义在被提交到 Kubernetes 集群后,可能存在许多个修改者,比如 CLI 工具、系统 controller、第三方 operator ,等等。它们都可以采取各自偏好的方式来修改资源定义。用前面的 Deployment 再来做个简单的演示。
在 nginx-deployment 的 Deployment 资源定义中,副本数(replicas)被设置为 1。因此执行 kubectl apply 后,集群中实际运行的副本数也是 1 :
❯ kubectl get deploy/nginx-deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 1/1 1 1 24h
这时,假设出现了另一个修改者,他跳过了本地 YAML 文件,直接用 kubectl edit 命令,将副本数调整成了 2:
# 第二位修改者:kubectl edit
❯ kubectl edit deploy/nginx-deployment
# .. 将其中的 replicas 字段修改为 2 后保存
# 修改生效,副本数变成了 2
❯ kubectl get deploy/nginx-deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 2/2 2 2 24h
最后再回到 kubectl apply。在不知道副本数已改变的情况下,重新执行 kubectl apply -f test_nginx.yaml,我们会发现副本数马上变回了 1。
❯ kubectl apply -f test_nginx.yaml
deployment.apps/nginx-deployment configured
❯ kubectl get deploy/nginx-deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 1/1 1 1 24h
也就是说, kubectl apply 直接重置了第二位修改者对副本数的改动。换句话说,kubecl apply 无法感知和处理多方修改的冲突场景,导致其他修改者的改动丢失。
除了冲突处理能力不佳,客户端侧 apply 还有许多其他问题。比方说,虽然 apply 命令功能强大,但大部分实现都在 kubectl 中,是 kubectl 的专属命令。如果其他客户端想进行“类似 apply”的资源操作,则需要自行实现“三路合并”算法,成本相当高。
正因为以上种种问题,2018 年 3 月,社区起草了一篇名为 Apply 的项目改进提议:KEP-555 。在提议中,人们设计了一种 kubectl apply 的一种全新实现:服务端侧 apply。
服务端侧 apply
如果用一句话来总结服务端侧 apply,可以说:服务端侧 apply 将“apply”从一个客户端功能变成了一种服务端的内置功能,用户只要发起一个简单的 API 请求,便能调用 apply 算法来“应用”一份资源定义。它带来了许多显而易见的好处。
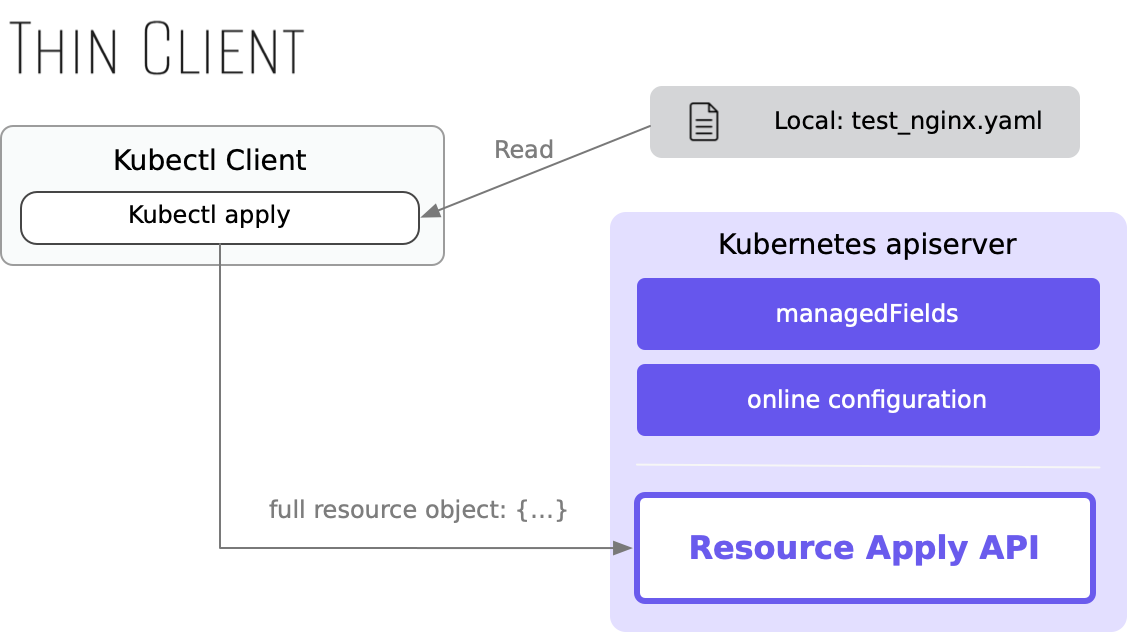
首先,客户端 kubectl 变得更简单了,它不再需要在本地进行复杂的“三路合并”,而是抄起本地资源,丢给 apply 接口即可。同时,任何第三方脚本、服务,都可以直接使用 apply 这种方便的资源修改能力,便利至极。
其次,服务端侧 apply 极大提升了多方修改场景下的冲突探测能力。
在客户端侧 apply 方案下,Kubernetes 通过系统注解 kubectl.kubernetes.io/last-applied-configuration 保存了上一次 apply 的完整数据,以此生成“智能补丁”,一定程度上回避了部分冲突。
而服务端 apply 采用了一种更为彻底的冲突解决模式。它在系统字段 managedFields 中,存下了资源的每个字段的修改者。基于 managedFields 中的数据,服务端得以快速识别出每个可能发生数据冲突的场景,给用户提供必要的信息,以避免发生意料外的数据覆盖。
举例来说,如果是服务端 apply,那么在上一节执行最后一次 apply 命令时,服务端会直接提示数据冲突报错:
❯ kubectl apply --server-side -f test_nginx.yaml
error: Apply failed with 1 conflict: conflict with "kubectl-edit" using apps/v1: .spec.replicas
Please review the fields above--they currently have other managers. Here
# ...
此时,用户既可强制写入数据,也可放弃对冲突字段的管理权(删除该字段),总之,服务端侧 apply 给了用户气定神闲处理冲突的机会。
小结
通过将逻辑从客户端移动到服务端,Kubernetes 的 apply 功能获得了更好的冲突处理能力,也变得更为易用。在新设计中,客户端 kubectl 由胖变瘦,服务端 apiserver 从瘦变胖。
如果你想更深入地了解 kubectl apply,可以阅读以下文档:
软件设计建议
客户端是胖还是瘦,在于所承受的职责多少,胖瘦并无高下之分,只是各自适合的场景有所不同。选胖还是选瘦?多数情况下这答案是显而易见的,因为许多功能天然只适合某种实现。就像全局搜索,只会是“瘦客户端,胖服务端”——它依赖服务端数据库里的全部数据。
让我们头疼的,往往是那些答案不够显而易见、模棱两可的情况。这时,如何挑选更恰当的策略?以下是我的几条建议。
1. 善用服务端功能零成本复用、变更实时触达的特点
回顾 kubectl apply 的演进过程,可以发现“服务器端 apply”相比“客户端 apply”的一大优势是它能轻松支持多种不同客户端。服务器端 apply,不光 kubectl 工具能用,任何一个人直接抄起 curl 也能用,毕竟它无需任何本地计算,只需要发起一个普通的 HTTP 请求即可。
正因如此,当你在纠结应当采用“瘦客户端”还是“胖客户端”时,请向自己提一个问题:“该功能有可能(需要)被多种不同客户端使用吗?” 如果答案是肯定的,那么“瘦客户端”可能是更优的选择。
除了能“零成本”复用外,在服务端实现功能的另一个好处是变更能实时触达用户。
在许多场景中(如移动端软件开发),发布一个新客户端版本需要层层审核,变更无法实时推送到用户侧。这时,“瘦客户端,胖服务端”设计就有了很大的优势。功能有变更?只需更新一下服务端代码或配置即可。
2. 别让服务端因客户端的定制需求过载
《论语》有云:过犹不及。有些情况下,假如我们过度追求“瘦客户端”,将所有复杂度一股脑塞进服务端,会导致后者不必要的臃肿,反而催生出不好的设计。
这次我们换换口味,不说软件,用一家烤肉店来举例。
烤肉店故事:如何调味?
软件市的设计二路上新开了一家烤肉店,主打烤肉口味丰富。
为符合各类顾客的口味偏好,店内烤肉提供了多种不同风味,如甜辣、咸甜、酸辣,等等。同时,遵循“顾客至上”的原则,烤肉店采取了后厨调味的策略:顾客在点单时标记想吃的口味,后厨在备肉时调好味。 刚开始,这样的方式很受用户欢迎。
一个月后,店内生意越来越好,许多五湖四海的顾客慕名而来。这时后厨发现,更多的顾客带来了烤肉口味的爆炸性增长,一天下来,自己需要调配出几十种不同口味满足顾客,忙得眼冒金星。
面对困境,老板小 R 想到了一个天才般(才怪)的解决办法:让顾客自助调味。在每张餐桌上,摆好辣椒、番茄酱、椒盐、酱油等五花八门的调味料,后厨只负责完成对肉完成基础处理(腌点盐),客人喜欢什么口味,自己添加即可。
切换成这种模式后,后厨压力得以释放,餐厅的运作效率得到了极大提升。
识别服务端复杂度的过载风险
就像“给肉调味”,在客户端/服务端架构中,天生有一类功能是更为贴近用户和客户端的,这类功能就是针对不同用户和客户端的定制化需求。
如果服务端总是一视同仁,尽全力满足所有用户和客户端的定制化需求,那么这虽然方便了客户端,自己却极易因复杂度过度增长而过载,导致后续很难维护。
因此,在软件开发过程中,开发者们需要敏锐地识别出这种过载风险。如判断某功能天生与客户端更为亲近,且不同客户端可能有不同的定制需求,那服务端最好点到即止,只提供基础功能,将更多定制逻辑交由客户端处理,切忌越俎代庖。
3. 客户端的计算力是独特的优质资源
在可供运用的计算(存储)资源层面上,服务端与客户端天生不同:
- 服务端:计算能力强大且集中,但单价通常较昂贵,以及和用户间隔着客户端;
- 客户端:直接触达用户,但可供调配的计算能力有限;每个用户通常独享客户端——每单位弱但数量多
这些特点将如何影响软件设计?还是通过烤肉店故事来看看。
烤肉店故事:谁来烤肉?
除了风味多种多样,设计二路上的烤肉店还有另一个杀手锏:服务员代烤肉。肉送到餐桌后,剪肉、摊肉、翻面、滋油,烤肉所需的各项劳动全都由服务员完成,顾客不需要动一个手指头。
同“后厨调味”一样,开业前一个月,这种代烤肉模式运作得非常好。但很快,老板小 R 发现这种模式难以为继。因为为了保证“代烤肉”服务的效率,店里需要为每一桌顾客配一位全职烤肉的服务员。这直接导致店内人员成本高涨,入不敷出。
发愁好几天后,小 R 又蹦出一个天才般(才怪)的想法:“为什么不让每个顾客自己动手呢?”
说干就干,第二天,烤肉店就变成了自助模式。每位来店用餐的顾客都需要自己烤肉,不再有服务员代劳。于是,烤肉店终于不用再雇佣海量服务员,很快扭亏为盈。
善用客户端的独特资源
如果用软件设计来类比,故事中烤肉店的变化,其实是一个从“瘦客户端”到“胖客户端”的变化:
- “服务员代烤肉” = “瘦客户端”:烤肉需要人来付出劳动,而这主要由烤肉店服务员(服务端资源)完成;
- “顾客自助烤肉” = “胖客户端”:烤肉所需的劳动,不再由烤肉店(服务端)承担,而是由每一个顾客(客户端)完成;
- 作为客户端,顾客天生拥有“自己动手烤肉”这种计算能力,“胖客户端”设计合理利用了这种能力,将服务端(烤肉店)的烤肉需求分摊了出去。
综上所述,和服务端有所不同,客户端拥有独特的优质资源(计算/存储),并且随着用户数量增长,这种资源天然呈现出水平扩展的特点。如果软件能利用好这份资源,去采用“胖客户端”设计,往往可以出奇制胜。
“自助烤肉”的弊端
再回到烤肉店,当“代烤肉”变成“自助烤肉”后,店内支出虽然变少,但整个就餐体验也发生了天翻地覆的变化。
如果说“服务员代烤肉”提供的是一种标准化的服务,总能让顾客吃到火候恰到好处的食物,“自助烤肉”所带来的就餐体验,其实是反标准化、参差不齐的。一些擅长烤肉的顾客,确实能吃到美味的肉,但部分动手能力较差的顾客,则很有可能在焦糊味中度过一个糟糕的夜晚。
这很好揭示了一个事实:不同于服务端,客户端天生就是层次不齐、不可靠的。不同客户端因其可调配的资源不同,提供的用户体验可能天差地别。在一些特殊领域(比如电子游戏)中,客户端的这种不可靠性,会成为软件设计时的一个重要考量。
结语
以 kubectl apply 的变迁史开头,本文对软件设计时的“胖/瘦客户端”进行了简单介绍,在末尾,我总结了一些与之相关的软件设计建议。希望这些内容能对你有所启发。
文末彩蛋
虽然服务端侧 apply 很好,但它目前仍未成为 kubectl apply 的默认选项,截止到目前,人们仍需要显式传入 --server-side 选项来启用服务端侧 apply。
服务端侧 apply 的稳定版本发布于 2021 年 8 月,距今已长达四年。修改一项客户端的默认行为,四年都无法完成,维护 Kubernetes 这种巨无霸软件背后的难度,可想而知。
相关讨论:kubectl: Use Server-Side-Apply by default · Issue #3805 · kubernetes/enhancements
题图来源:Photo by Isaac N.C. on Unsplash
😊 如果你喜欢这篇文章,也欢迎了解我的书: 《Python 工匠:案例、技巧与工程实践》 。它专注于编程基础素养与 Python 高级技巧的结合,是一本广受好评、适合许多人的 Python 进阶书。